First steps in parallel file access using MPI I/O
If your code uses MPI for parallelization, then you may want to use MPI I/O for writing and reading data from files in parallel. It is common to see the use of POSIX parallel approach where each MPI process reads/writes a separate file. This approach has the following drawbacks:
- Not efficiently scalable for very high number of processes
- Creates a large clutter in the file system and almost unmanageable when thousands of processes are used
MPI I/O fixes these problems and provides an elegant solution for MPI applications. It is very easy to read/write data in parallel using MPI I/O if you are familiar with the basics of MPI communications (viz. point-to-point, collective). In this article, I will show you how to do this with a simple example. The entire code (written in C) can be found in full in my Github repo MPI_Notes/MPI_IO.
Parallel file writing can be thought of in the following way. Say, we have 10 people trying to write something to the same notebook. Instead of passing the notebook to them one by one, we want to tell everyone where they should start writing (e.g. the page number) their part so they can all write at the same time. Obviously, we don’t want any of them to overwrite what others have written. So we need to have the page numbers for each person calculated correctly based on:
- How much would be written by others before the current person writes their part? This is called ‘displacement’
- How much we expect this person to write? This is the ‘length/count of the data’
In the case of POSIX parallel I/O, we would simply be giving separate notebooks to each person and let them write whatever they want. So, we don’t have to calculate the above things. But then, it is a lot of notebooks to carry around! It may not be possible to distribute and collect back these many notebooks in a short time as well.
Let us assume that we have 6 MPI processes in our code. And each of them have some data in a character array as shown below:
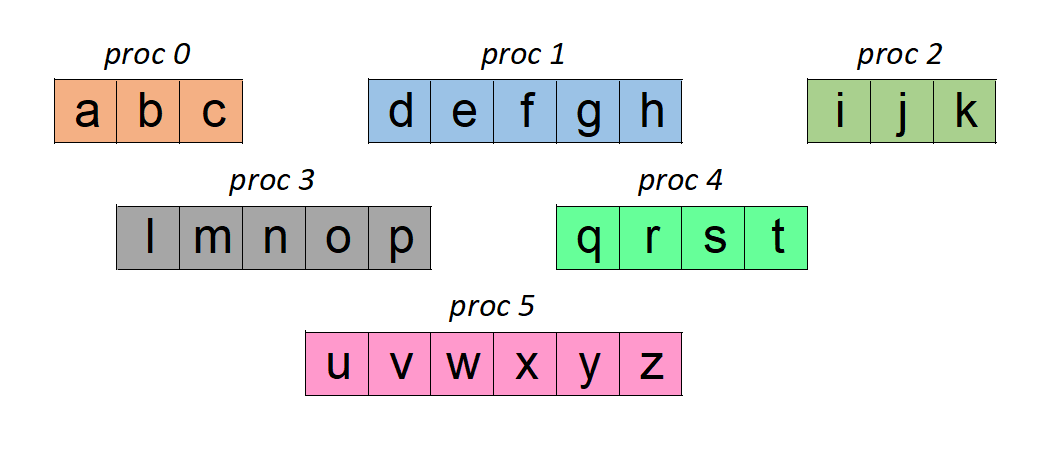
We shall ask this data to be written to a single file. And we expect the final data to be in order of the ranks, thus listing all the alphabets in sequence. There are three ways to do this in MPI I/O:
- Explicit offset
- Individual file pointers
- Shared file pointers
Using explicit offsets
As the name implies, we simply calculate the location where each process needs to write. This is usually specified as an ‘offset’/’displacement’ from the beginning of the file. In our example, proc 0 should write at the beginning of the file (after 0 characters), proc 1 should start writing after 3 characters (that would be written by proc 0), proc 2 should start writing after 8 characters (to take into account data from proc 0 and proc 1) and so on. Clearly, every process needs to know only where it should start writing. Additionally, we also need to inform MPI about how much data would be written.
Both this information should be supplied in the units of the datatype we are writing. In this example, the data is made of characters (these are MPI_CHAR type). The following code snippet opens/creates a file for parallel access by MPI I/O and the writes the data using the explicit offset approach collectively: (Full code here)
MPI_File_open(MPI_COMM_WORLD, "file_exp_offset.dat", MPI_MODE_CREATE|MPI_MODE_WRONLY, MPI_INFO_NULL, &file_handle);
MPI_File_write_at_all(file_handle, displacement, test_txt, arr_len_local, MPI_CHAR, MPI_STATUS_IGNORE);
MPI_File_close(&file_handle);Once we run the program with 6 MPI processes, we will have the file “file_exp_offset.dat” written to disk. As we have written character data, we can view the contents of this file in any text editor. The file contains the following:
abcdefghijklmnopqrstuvwxyzUsing individual file pointers
When a file is opened using MPI_File_open() command, MPI creates an individual file pointer for each MPI process so that it tracks the position in file of that process. It is very similar to the file pointer in C, for example, but maintained for each MPI process separately. Note that this pointer could be in different position in the file for different processes. Using this individual file pointer, it is possible to read/write data conveniently to file in parallel. While it is possible to set the individual pointers manually per process, the most common way is to inform MPI about the global view of the data we are planning to write. Let me explain.
In our example, this can be achieved by:
// Create a MPI datatype for the global array
MPI_Type_create_subarray(1, &total_len, &arr_len_local, &disp, MPI_ORDER_C, MPI_CHAR, &char_array_mpi);
MPI_Type_commit(&char_array_mpi);The above snippet creates a MPI datatype called ‘char_array_mpi’ which describes the global view of the data. ‘total_len’ is the total length of global data, ‘arr_len_local’ is the length of the data in the current process and ‘disp’ gives the displacement of the local data in the global array that we described earlier.
Once the global datatype is created, we inform MPI I/O by setting a ‘File View’ as follows:
MPI_File_set_view(file_handle, 0, MPI_CHAR, char_array_mpi,"native", MPI_INFO_NULL);‘File View’ essentially changes the way the file is accessed. MPI now knows that our read/write operations are towards reading/writing data of type ‘char_array_mpi’ and each individual process will contain only the local data for this datatype. It also additionally knows that every element we shall write is of type MPI_CHAR. This command also moves the individual (and shared) file pointer positions to the correct locations as per the global datatype (and redefines them as zero position of those pointers).
After setting the ‘File View’, we can write our character arrays to file using:
MPI_File_write_all(file_handle, test_txt, arr_len_local, MPI_CHAR, MPI_STATUS_IGNORE);The complete code snippet is:
MPI_File_open(MPI_COMM_WORLD, "file_ind_ptr.dat", MPI_MODE_CREATE|MPI_MODE_WRONLY, MPI_INFO_NULL, &file_handle);
MPI_File_set_view(file_handle, 0, MPI_CHAR, char_array_mpi,"native", MPI_INFO_NULL);
MPI_File_write_all(file_handle, test_txt, arr_len_local, MPI_CHAR, MPI_STATUS_IGNORE);
MPI_File_close(&file_handle);While this may seem a bit tedious, this approach can be used to write more complex datatypes and partitioning commonly used in MPI applications. Also, note that we can repeatedly write the same datatype again if needed without much additional effort. If we want to read/write a different type of data, we need to change the ‘File View’.
Using shared file pointers
One important point to note is that individual file pointers are what they claim to be, only ‘individual’. The processes do not know about how individual pointers of other processes move about. There are some situations where every MPI process needs to have a synchronized file pointer. For this purpose, MPI maintains a single shared file pointer for every MPI I/O file opened. When a read/write is done using this shared file pointer, every MPI process knows about a change in the shared file pointer position. For the sake of completeness, we shall demonstrate the collective writing of data using this approach in our example. The following code snippet writes using the shared file pointer:
MPI_File_open(MPI_COMM_WORLD, "file_shr_ptr.dat", MPI_MODE_CREATE|MPI_MODE_WRONLY, MPI_INFO_NULL, &file_handle);
MPI_File_write_ordered(file_handle, test_txt, arr_len_local, MPI_CHAR,MPI_STATUS_IGNORE);
MPI_File_close(&file_handle);Note that the displacements are calculated on the fly by MPI in this case as we are using the shared file pointer (because of the call to ‘MPI_File_write_ordered’). But this will come with a performance penalty as well.
Please go through the entire code here as it provides all the details. I have simplified a lot of things in this article but this is enough to get you started with MPI I/O. In the next article, we shall see how to read back the data in parallel.