Reading data in parallel using MPI I/O
In the previous post “First steps in parallel file access using MPI I/O”, we discussed how to write some simple data in parallel using MPI I/O. Here we shall read back that data in parallel. The entire code is given in my GitHub repo MPI_Notes. Essentially, we have the following text data in a file:
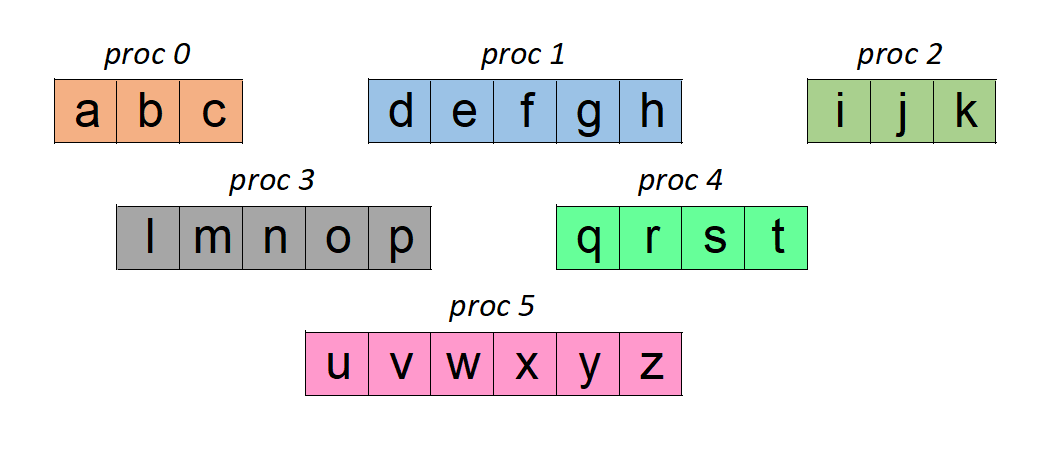
abcdefghijklmnopqrstuvwxyzWe will try to read this using 6 MPI processes. And we want each process to read a part of this data as shown below: (this is the same partitioning used when we wrote the data)

This partitioning is arbitrary and we could have chosen different ways to divide up the data among processes to read. Similar to the writing process, there are three approaches in MPI I/O which can be used to read this data:
- Using explicit offsets
- Using individual file pointers
- Using shared file pointers
Using explicit offsets
As the name suggests, we need to calculate where each process should start reading its data (‘offset’) and the length of the data to be read in by that process (‘count’). So, proc 0 should read at the beginning of the file (3 characters to be read), proc 1 should start writing after 3 characters (5 characters to be read), proc 2 should start reading after 8 characters (3 characters to be read) and so on. This can be done by the following piece of code:
MPI_File_open(MPI_COMM_WORLD, "file_exp_offset.dat", MPI_MODE_RDONLY, MPI_INFO_NULL, &file_handle);
MPI_File_read_at_all(file_handle, disp, test_txt,arr_len_local,MPI_CHAR,MPI_STATUS_IGNORE);
MPI_File_close(&file_handle);‘disp’ denotes the offset calculated and ‘arr_len_local’ is the count (length) of the data to read in. Once the data is read in, the MPI processes will have the following data in their ‘test_txt’ array:
While the explicit offset approach seems quite straightforward, it is preferable to use the individual file pointer method for more complex datasets and partitioning. This is discussed next.
Using individual file pointers
Since we have explained the individual file pointer method in the previous post, we shall only outline the approach here. Instead of calculating individual file pointer locations manually, we define a new global datatype to represent the data partitioning. This is done by:
MPI_Type_create_subarray(1, &total_len, &arr_len_local, &disp, MPI_ORDER_C, MPI_CHAR, &char_array_mpi);
MPI_Type_commit(&char_array_mpi);Once the global datatype is created like this, reading the data in parallel is very simple as shown below:
MPI_File_open(MPI_COMM_WORLD, "file_ind_ptr.dat", MPI_MODE_RDONLY, MPI_INFO_NULL, &file_handle);
MPI_File_set_view(file_handle, 0, MPI_CHAR, char_array_mpi,"native", MPI_INFO_NULL);
MPI_File_read_all(file_handle, test_txt, arr_len_local, MPI_CHAR, MPI_STATUS_IGNORE);
MPI_File_close(&file_handle);Using shared file pointers
In the shared file pointer approach, we specify simply the ‘count’ of the data to be read by each process and let MPI calculate the offsets for us. This can be achieved by the following code snippet:
MPI_File_open(MPI_COMM_WORLD, "file_shr_ptr.dat", MPI_MODE_RDONLY, MPI_INFO_NULL, &file_handle);
MPI_File_read_ordered(file_handle, test_txt, arr_len_local, MPI_CHAR,MPI_STATUS_IGNORE);
MPI_File_close(&file_handle);Of course, this will come with a performance penalty as the shared file pointer is synchronized internally by MPI. The approach to use for reading/writing should be tested and its performance evaluated before deploying for production use in a software.
For demonstration purposes, we have chosen to read/write some character array in the examples here. We shall look into writing/reading general numerical data in some complex data partitioning in the next articles in this series on MPI I/O.